kubernetes-notes
1. Controller Manager简介
Controller Manager作为集群内部的管理控制中心,负责集群内的Node、Pod副本、服务端点(Endpoint)、命名空间(Namespace)、服务账号(ServiceAccount)、资源定额(ResourceQuota)的管理,当某个Node意外宕机时,Controller Manager会及时发现并执行自动化修复流程,确保集群始终处于预期的工作状态。

每个Controller通过API Server提供的接口实时监控整个集群的每个资源对象的当前状态,当发生各种故障导致系统状态发生变化时,会尝试将系统状态修复到“期望状态”。
2. Replication Controller
为了区分,将资源对象Replication Controller简称RC,而本文中是指Controller Manager中的Replication Controller,称为副本控制器。副本控制器的作用即保证集群中一个RC所关联的Pod副本数始终保持预设值。
- 只有当Pod的重启策略是Always的时候(RestartPolicy=Always),副本控制器才会管理该Pod的操作(创建、销毁、重启等)。
- RC中的Pod模板就像一个模具,模具制造出来的东西一旦离开模具,它们之间就再没关系了。一旦Pod被创建,无论模板如何变化,也不会影响到已经创建的Pod。
- Pod可以通过修改label来脱离RC的管控,该方法可以用于将Pod从集群中迁移,数据修复等调试。
- 删除一个RC不会影响它所创建的Pod,如果要删除Pod需要将RC的副本数属性设置为0。
- 不要越过RC创建Pod,因为RC可以实现自动化控制Pod,提高容灾能力。
2.1. Replication Controller的职责
- 确保集群中有且仅有N个Pod实例,N是RC中定义的Pod副本数量。
- 通过调整RC中的spec.replicas属性值来实现系统扩容或缩容。
- 通过改变RC中的Pod模板来实现系统的滚动升级。
2.2. Replication Controller使用场景
| 使用场景 | 说明 | 使用命令 |
|---|---|---|
| 重新调度 | 当发生节点故障或Pod被意外终止运行时,可以重新调度保证集群中仍然运行指定的副本数。 | |
| 弹性伸缩 | 通过手动或自动扩容代理修复副本控制器的spec.replicas属性,可以实现弹性伸缩。 | kubectl scale |
| 滚动更新 | 创建一个新的RC文件,通过kubectl 命令或API执行,则会新增一个新的副本同时删除旧的副本,当旧副本为0时,删除旧的RC。 | kubectl rolling-update |
滚动升级,具体可参考kubectl rolling-update –help,官方文档:https://kubernetes.io/docs/tasks/run-application/rolling-update-replication-controller/
3. Node Controller
kubelet在启动时会通过API Server注册自身的节点信息,并定时向API Server汇报状态信息,API Server接收到信息后将信息更新到etcd中。
Node Controller通过API Server实时获取Node的相关信息,实现管理和监控集群中的各个Node节点的相关控制功能。流程如下
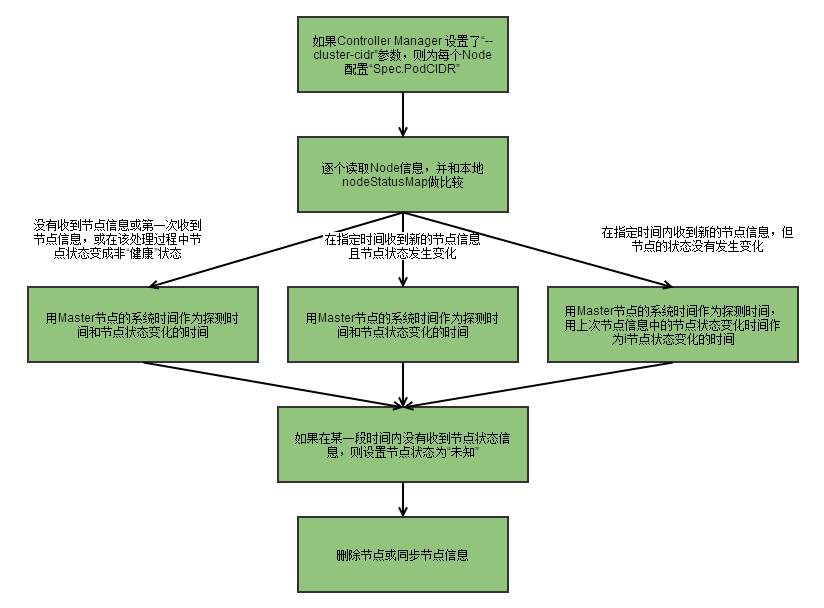
1、Controller Manager在启动时如果设置了–cluster-cidr参数,那么为每个没有设置Spec.PodCIDR的Node节点生成一个CIDR地址,并用该CIDR地址设置节点的Spec.PodCIDR属性,防止不同的节点的CIDR地址发生冲突。
2、具体流程见以上流程图。
3、逐个读取节点信息,如果节点状态变成非“就绪”状态,则将节点加入待删除队列,否则将节点从该队列删除。
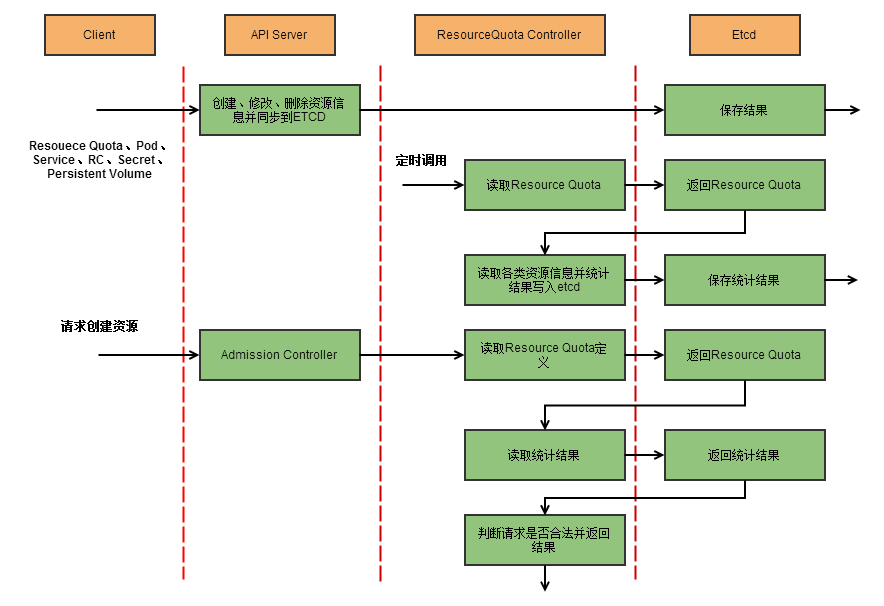
4. ResourceQuota Controller
资源配额管理确保指定的资源对象在任何时候都不会超量占用系统物理资源。
支持三个层次的资源配置管理:
1)容器级别:对CPU和Memory进行限制
2)Pod级别:对一个Pod内所有容器的可用资源进行限制
3)Namespace级别:包括
- Pod数量
- Replication Controller数量
- Service数量
- ResourceQuota数量
- Secret数量
- 可持有的PV(Persistent Volume)数量
说明:
- k8s配额管理是通过Admission Control(准入控制)来控制的;
- Admission Control提供两种配额约束方式:LimitRanger和ResourceQuota;
- LimitRanger作用于Pod和Container;
- ResourceQuota作用于Namespace上,限定一个Namespace里的各类资源的使用总额。
ResourceQuota Controller流程图:
5. Namespace Controller
用户通过API Server可以创建新的Namespace并保存在etcd中,Namespace Controller定时通过API Server读取这些Namespace信息。
如果Namespace被API标记为优雅删除(即设置删除期限,DeletionTimestamp),则将该Namespace状态设置为“Terminating”,并保存到etcd中。同时Namespace Controller删除该Namespace下的ServiceAccount、RC、Pod等资源对象。
6. Endpoint Controller
Service、Endpoint、Pod的关系:
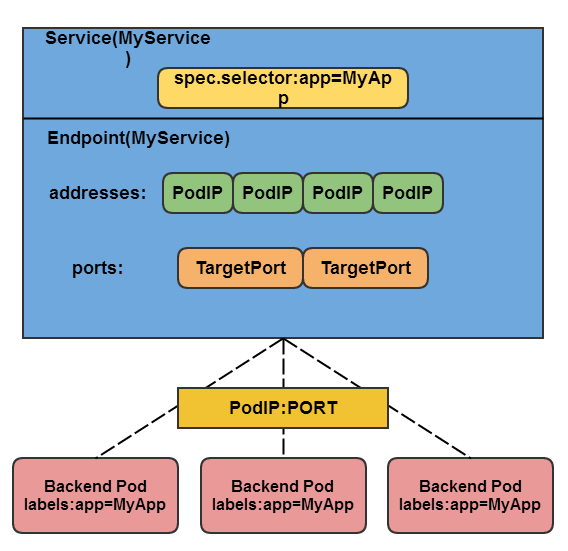
Endpoints表示了一个Service对应的所有Pod副本的访问地址,而Endpoints Controller负责生成和维护所有Endpoints对象的控制器。它负责监听Service和对应的Pod副本的变化。
- 如果监测到Service被删除,则删除和该Service同名的Endpoints对象;
- 如果监测到新的Service被创建或修改,则根据该Service信息获得相关的Pod列表,然后创建或更新Service对应的Endpoints对象。
- 如果监测到Pod的事件,则更新它对应的Service的Endpoints对象。
kube-proxy进程获取每个Service的Endpoints,实现Service的负载均衡功能。
7. Service Controller
Service Controller是属于kubernetes集群与外部的云平台之间的一个接口控制器。Service Controller监听Service变化,如果是一个LoadBalancer类型的Service,则确保外部的云平台上对该Service对应的LoadBalancer实例被相应地创建、删除及更新路由转发表。
参考《Kubernetes权威指南》